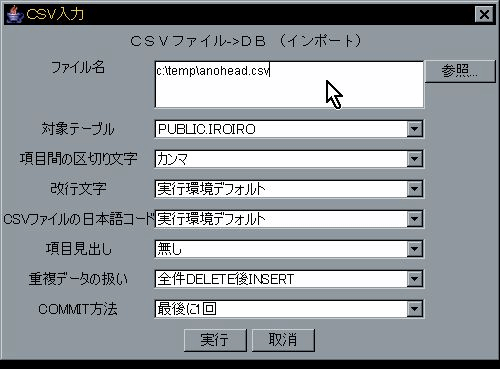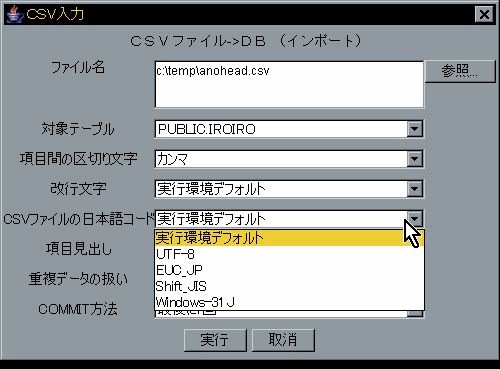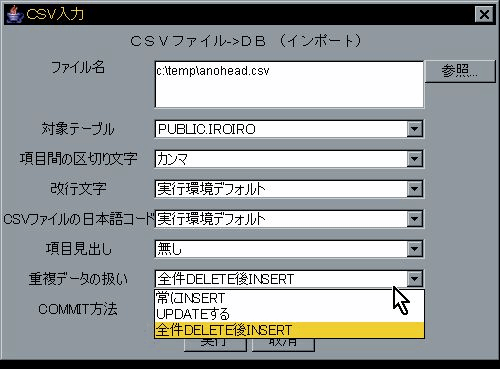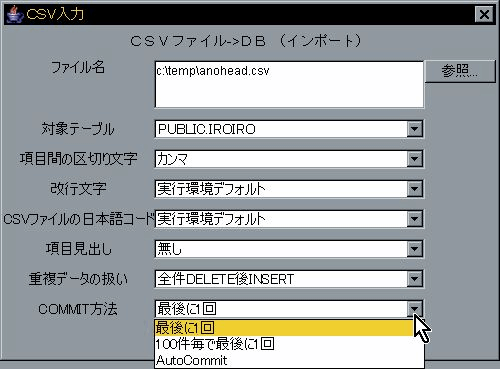
既存データがあった時の動作が特徴で、updateとinsertの自働判断も指定できます。 具体例による機能紹介 も参考にして下さい。 詳細なファイル仕様は CSVファイルの仕様 にまとめてあります。
”いまいち何が起こるのか分からない” ”本当に大丈夫か?” と思う時は、迷わずDBMS機能でバックアップしてから使用して下さい。
既存データに対してどのようにINSERTするか?を切り替える事が出来ます。
データの存在チェックをせず、入力データを常にINSERTします。主キーの無いテーブルに対してインポートする時を想定してます。
主キーのあるテーブル(一意性制約付きのテーブル)で一意性制約が発生した場合は、その時点でrollbackを発行し終了します。
最初に DELETE * FROM テーブル を行ってから、INSERTを行います。テーブル内容を全部入れ替える時を想定してます。
主キーで検索を行い、存在した場合はUPDATE、存在しない場合はINSERTを行います。WHERE句を自動生成する為制限があります。
「UPDATE」の変形で、データが存在しない場合のみINSERTを行います。存在した場合は入力データを読み飛ばします。制限は「UPDATE」と同じです。
CSVの項目順が、テーブル定義のカラム順に完全一致している場合に使用します。過不足があっても駄目です。
発行されるSQL文は INSERT
INTO テーブル名 VALUES(データ....); です。
CSVの項目順と項目数が、テーブル定義と異なる場合に使用します。テーブルにカラム追加があって、もとりあえずインポート出来ます。 発行されるSQL文は INSERT INTO テーブル名 (カラム名...) VALUES(データ....); です。
「重複データの扱い」と「項目見出し」を組み合わせれば、たぶんいろいろできると思うのですが、ややこしい気もします。 機能はこのままでGUIだけでも改善すれば、使いやすくなるかもしれません。
ちなみに、自分が良く使うのは以下の組み合わせです。
時々”エラーが発生するまでとにかくインポート”という気分になるので、「COMMIT方法」=「AutoCommit」でヤケッパチインポートもします。
最初にCSVファイルを用意する時、カラム名を設定するのは面倒なのですが、以下のいずれかで簡単に作れます。
本ツールで認識するCSVファイルの形式を示します。
| 説明 | インポート(入力) | エクスポート(出力) | |
|---|---|---|---|
| カラム名 | CSVなのでカラム名を持てないのですが、CSVファイルの1行目をカラム名行として扱えます。また、カラム行が存在せず1行目からデータが始まる指定も出来ます。 | 実行画面で切替 | ← |
| 項目区切り | 1行内の各項目の区切りは、タブ又はカンマを指定出来ます。 | 実行画面で切替 | ← |
| 文字コード | ファイルの文字コードは、Java実行環境デフォルト UTF-8 EUC_JP Windows-31J Shift_JIS のいずれかを指定できます。ファイル入出力時にUNICODEとの変換で使用されます。DBへのアクセス時は一切影響しません。 | 実行画面で切替 | ← |
| 行区切り(改行コード) | 出力時改行コードは Java実行環境デフォルト \n \r\n \r のいずれかを指定できます。入力時は自働判定しますので指定しても無視されます。但し、クォートで括られた中の改行コードは行区切に認識されず、そのままデータとして扱われます。 | 自働判定 | 実行画面で切替 |
| クォート文字 | ダブルクォートのみです。データにタブ、カンマ、改行コードを含む時は文字列全体をダブルクォートで括ります。入力時に、先頭と終端のクォート文字は捨てられ、DBへは更新されません。 ダブルクォート文字をデータとして扱う時はダブルクォートを連続させてください。 | 自働判定 | 自働付与 |
| SQLのヌル(NULL)値データ | ヌル値は、#$%&NULL&%$# という文字列データとしてCSV上表現します。入出力時に、#$%&NULL&%$# と SQLのNull値は自動変換されます。なお、この文字列は設定画面で変更できます。 | デフォルトでは #$%&NULL&%$# | ← |
| 空白 | 空白は特別な意味を持ちません。また、自動的に切り捨てられる事もありません。例えば「△"あ"△」は「△あ△」として扱われます。 | 特殊文字でない | ← |
| 数値項目 |
入力時は、数値であっても全て文字列としてJDBCドライバに渡されます。文字列->
数値変換は、JDBCドライバに任せています。 また、クォート文字で括られていても構いません。例えば「”123”」の場合、ツールで文字列の「123」になり、JDBCドライバが必要に応じて変換します。 |
JDBCドライバが変換 | toString()で文字列化 |
| バイナリデータ | 16進表現文字列として扱います。例えば、バイナリデータの「X"0123"」は、CSVファイル上は「"0123"」(=X"30313233")となります。16進文字列 <-> バイナリデータの変換はテーブル定義を参照し自動的に行われ、任意に指定する方法は現在ありません。 | 自働変換 | 自働変換 |
ファイルの内容を先頭100件迄プレビューする機能があり、ツールでどのように読み取られるかを確認できます。100件以内でカラム数に不一致があるか?も検出できます。
Importのいろいろな実行例を紹介します。
以下のテーブルがあったとして、
|
bookid INTEGER |
title VARCHAR(30) |
Murderer VARCHAR(10) |
price NUMERIC(8) |
| 1 | そして誰もいなくなった | 死んじゃったの? | 600 |
| 2 | アクロイド殺し | そんなの反則 | 650 |
| 3 | オリエント急行の殺人 | 信じられん | 700 |
色付き部分のように更新したいとします。bookidが主キーです。
|
bookid INTEGER |
title VARCHAR(30) |
murderer VARCHAR(10) |
price NUMERIC(8) |
| 1 | そして誰もいなくなった | 死んじゃったの? | 600 |
| 2 | アクロイド殺し | そんなの反則 | 750 |
| 3 | オリエント急行の殺人 | 信じられん | 800 |
| 4 | #null# | #null# | 850 |
このようなCSVファイルを用意し、
bookid,price
2,750
3,800
4,850
CSV入力画面で、『項目見出し:
有り
、重複データの扱い:
UPDATEする
』を必ず指定します。
指定例はこんな感じ
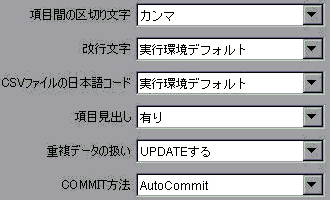
テーブルに主キーが定義されている事と、CSVファイルの一行目がカラム名である事が必要です。これは実際に発行されるSQLを考えれば、納得してもらえると思います。
以下のようなSQL文が実際に発行されます。
UPDATE xxxx SET bookid = 2 , price = 750 WHERE bookid = 2; 【auto commit;】
UPDATE xxxx SET bookid = 3 , price = 800 WHERE bookid = 3; 【auto commit;】
UPDATE xxxx SET bookid = 4 , price = 850 WHERE bookid = 4; 【auto commit;】
但し、存在しないので引き続き
INSERT xxxx ( bookid , price ) values (4 , 850 ); 【auto commit;】
先ほどの例はCSVファイルの内容全てをテーブルに反映するのですが、一致したデータは更新せず、存在しないデータだけ追加したい事もあると思います。
このような時は入力ファイルからデータ事前にを除けば良いのですが、面倒です。
つまり、以下のテーブルがあったとして、
|
bookid INTEGER |
title VARCHAR(30) |
Murderer VARCHAR(10) |
price NUMERIC(8) |
| 1 | そして誰もいなくなった | 死んじゃったの? | 600 |
| 2 | アクロイド殺し | そんなの反則 | 650 |
| 3 | オリエント急行の殺人 | 信じられん | 700 |
色付き部分を追加するとします。
|
bookid INTEGER |
title VARCHAR(30) |
murderer VARCHAR(10) |
price NUMERIC(8) |
| 1 | そして誰もいなくなった | 死んじゃったの? | 600 |
| 2 | アクロイド殺し | そんなの反則 | 650 |
| 3 | オリエント急行の殺人 | 信じられん | 700 |
| 4 | #null# | #null# | 850 |
このようなCSVファイルしかないとします。(この場合、2行目と3行目を削除すればよいのですが、データ数が多ければ面倒です。)
bookid,price
2,750
3,800
4,850
CSV入力画面で、『項目見出し:
有り
、重複データの扱い:
何もしない
』を必ず指定します。
指定例はこんな感じ

テーブルに主キーが定義されている事と、CSVファイルの一行目がカラム名である事が必要です。これは実際に発行されるSQLを考えれば、納得してもらえると思います。
以下のようなSQL文が実際に発行されます。
SELECT COUNT(*) FROM xxxx WHERE bookid = 2; 【auto commit;】
1件なので何もしない
SELECT COUNT(*) FROM xxxx WHERE bookid = 3; 【auto commit;】
1件なので何もしない
SELECT COUNT(*) FROM xxxx WHERE bookid = 4; 【auto commit;】
0件なので引き続き
INSERT xxxx ( bookid , price ) values (4 , 850 ); 【auto commit;】
『既存の行を削除したい時はどうすれば良いか?』 残念ながら、特定の行を削除する機能は無いので、全件削除後に追加するしかありません。
つまり、以下のテーブルがあったとして、
|
bookid INTEGER |
title VARCHAR(30) |
Murderer VARCHAR(10) |
price NUMERIC(8) |
| 1 | そして誰もいなくなった | 死んじゃったの? | 600 |
| 2 | アクロイド殺し | そんなの反則 | 650 |
| 3 | オリエント急行の殺人 | 信じられん | 700 |
色付き部分を追加するとします。
|
bookid INTEGER |
title VARCHAR(30) |
murderer VARCHAR(10) |
price NUMERIC(8) |
| 1 | そして誰もいなくなった | #null# | 600 |
| 5 | スタイルズ荘の怪事件 | #null# | 900 |
| 6 | カーテン | #null# | 950 |
このようなCSVファイルを用意します。カラム名を指定して処理されるので、項目の並びはどんな順番でも構いません。
また、mudererの値はCSVファイルに含まず、DEFAULT値で作成したいとします。
bookid,price,title
1,750,そして誰もいなくなった
5,900,スタイルズ荘の怪事件
6,950,カーテン
CSV入力画面で、『項目見出し:
有り
、重複データの扱い:
全件DELETE後INSERT
』を必ず指定します。
指定例はこんな感じ

以下のようなSQL文が実際に発行されます。where句を必要としないので、主キーの有無に関係なく実行できます。
DELETE FROM xxxx ;【auto commit;】
INSERT xxxx ( bookid,price,title ) values (1,750,そして誰もいなくなった ); 【auto commit;】
INSERT xxxx ( bookid,price,title ) values (5,900,スタイルズ荘の怪事件 ); 【auto commit;】
INSERT xxxx ( bookid,price,title ) values (6,950,カーテン ); 【auto commit;】
前述のSQL文中で、文字列を括るはずのクォートは、あえて記載しませんでした。値は、SQL文全体をテキストとしてJDBCドライバに渡すのではなく、Stringオブジェクトの引数として渡しています。通常SQL文をテキストとしてDBMSに渡す時は' 'で括ると思いますが、引数として渡すのでそのような考慮は不要という方針です。
これは『バイナリデータはオブジェクトで渡す』という処理を行う為です。
基本的にはテーブル定義データ型とは無関係にStringオブジェクトをJDBCドライバに渡しており、Stringオブジェクト=>テーブル定義データ型への変換はJDBCドライバに全て任しています。
例外はバイナリ系のデータ型です。Stringオブジェクトのままだと、文字コードの16進文字列表現として格納されてしまいます。その為、テーブル定義データ型がバイナリの時は、入力ファイルの16進文字列表現=>バイト配列変換を自前で行い、JDBCドライバへはバイト配列(byte[])を渡しています。
なお、バイナリとして扱うのは以下の時です。
switch (types) { //typesはテーブル定義のSQLデータ型(java.sql.Types)
case Types.BINARY:
case Types.BLOB:
case Types.LONGVARBINARY:
case Types.VARBINARY:
return true;
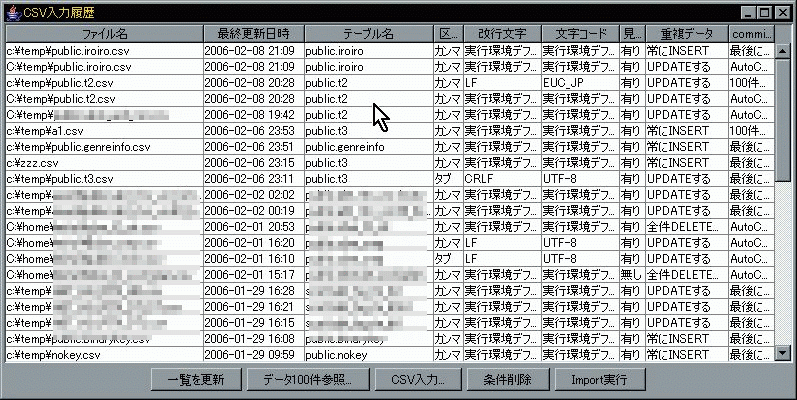
一度実行したCSV入力条件は保存され、下記画面から繰返し実行できます。